集合(Collection)是Java代码中的Backbone,其对各种数据类型的抽象为Java Developer的开发提供了极大的便利,因此熟悉集合的使用及了解集合的原理是Java Developer的基本功之一。
JCF
一个集合类的实例是若干个对象的集合,是数据结构类型的实例化结果,比如链表、映射表、队列等。由于复杂的类结构,所有Java集合相关的的接口以及类被统称为集合框架(JCF, Java Collections Framework),当然这个框架与我们通常所说的框架(e.g. Spring Framework)是不同的,个人认为称为体系可能更加贴切。
优势
使用JCF的优势主要集中在以下几点:
- 降低代码量和复杂度。
由于JCF已经设计实现了许多数据结构,因此(绝大多数情况下)不需再由Java Developer进行基础数据结构的设计;同时JCF的设计了一套集合API,可以直接使用,提高了代码复用性,降低了编码难度。 - 提升代码性能。
被JDK收录的集合类库是一系列数据结构类型的具体实现,其质量和性能较高,降低了底层代码的性能风险。
构成
JCF主要由以下几部分组成:
- 提供了一系列的集合接口,如
Set,List,Map等。 - 针对集合接口的通用实现,这些实现类实现了接口的基本功能,如
ArrayList,HashMap等。 - 针对集合接口的抽象类实现,这样的实现允许更多的定制,类名通常以
Abstract开头。 - 针对集合接口的包装类(Wrapper)实现,比如让接口只读。
- 针对集合接口的高性能且方便的功能性实现,比如数组转换成
List。 - 为早期的集合类添加了集合接口的实现,如
Vector,Hashtable等。 - 针对集合接口的某些特殊实现,如特殊的
List等。 - 针对集合接口的同步实现,这类实现通常以
Concurrent开头,是线程安全的,如ConcurrentHashMap等。 - 提供了针对集合的一些算法,如
Collections类提供的将一个List排序的算法。 - 针对集合接口的基础支持,如迭代器。
- 针对数组的工具类,严格来讲这些类不算JCF的一部分。
接口
接口可以分为两组,一组继承自java.util.Collection接口,包括:java.util.Setjava.util.SortedSetjava.util.NavigableSetjava.util.Queuejava.util.concurrent.BlockingQueuejava.util.concurrent.TransferQueuejava.util.Dequejava.util.concurrent.BlockingDeque
另一组继承自java.util.Map,包括:java.util.SortedMapjava.util.NavigableMapjava.util.concurrent.ConcurrentMapjava.util.concurrent.ConcurrentNavigableMap
通用实现
下面这张表展示了集合的通用实现类,第一列代表接口,后面几列代表具体实现了哪些功能,每一行代表既继承了对应行的接口又实现了对应列的功能的实现类。
| Interface | 哈希表 | 可变数组 | 平衡树 | 链表 | 哈希表 + 链表 |
|---|---|---|---|---|---|
| Set | HashSet | - | TreeSet | - | LinkedHashSet |
| List | - | ArrayList | - | LinkedList | - |
| Deque | - | ArrayDeque | - | LinkedDeque | - |
| Map | HashMap | - | TreeMap | - | LinkedHashMap |
除此之外,还有PriorityQueue,由于平时接触较少,就不介绍了。
抽象实现
集合接口的抽象实现类包括AbstractCollection、AbstractSet、AbstractList、AbstractQueue、 AbstractSequentialList以及AbstractMap等抽象类,它们提供了一些基本实现,同时让它们的继承类在最小限度地进行基本实现的同时进行定制。
包装类实现
包装类实现提供了增强功能,与其他实现配合使用,其只能通过静态工厂方法调用。
- Collections.unmodifiableInterface
为指定的集合提供一个只读的接口,如果用户尝试修改其中的元素将抛出UnsupportedOperationException。 - Collections.synchronizedInterface
为指定的集合提供一个同步的接口,保证了线程安全。 - Collections.checkedInterface
为指定的集合提供一个动态的类型安全接口,当添加的元素类型错误时抛出ClassCastException。虽然泛型机制保证了编译时的静态的类型安全,但仍然有可能绕过它,这个接口干掉了这种可能。
功能性实现
JCF提供了诸多高性能且方便的增强型功能,用于获取我们所需的集合对象。
最小实现
这些方法最小化地实现了接口,且保证了高性能。
- Arrays.asList
将一个数组转换为List集合。 - Collections.emptySet, Collections.emptyList, Collections.emptyMap
创建一个不可变的空Set、List或Map,如果试图修改其中的元素,将抛出UnsupportedOperationException。 - Collections.singleton, Collections.singletonList, Collections.singletonMap
创建一个不可变的只包含指定元素的单例Set、List,或一个不可变的只包含一对Key-Value的单例Map。 - nCopies
创建一个不可变的List,指定一个数目n和一个对象T,List的元素数为n,所有的元素均为T的复制。
适配器
根据设计模式中的适配器模式来设计,可以让一种集合接口适配另外一种。
- Collections.newSetFromMap(Map)
从Map适配到一个Set。 - Collections.asLifoQueue(Deque)
将Deque适配到一个LIFO的队列。
早期集合类增强
针对较旧的集合类,为其添加集合接口实现。
- Vector
同步的可变数组,实现了List接口,同时也包含其自身的一些较旧的方法。 - Hashtable
同步的哈希表,实现了Map接口,不允许null作为key或value,同时也包含其自身的一些较旧的方法。
特殊实现
- WeakHashMap
keys都是弱引用的Map,这样就能保证在垃圾回收时,key能被回收,导致value也能被回收,从而让对应的entry消失。 - IdentityHashMap
基于哈希表的实现,允许key重复,不调用equals方法,使用引用相等性而不是对象相等性来判断。 - CopyOnWriteArrayList
一种copy-on-write的List。所有修改操作,e.g. add, set, remove,均不直接对原对象进行操作,而是先copy一份,对新的对象进行操作,然后将原对象的引用指向这个新的对象。copy-on-write将读写分离,能保证对CopyOnWriteArrayList进行并发的读,且不用进行加锁等同步操作。 - CopyOnWriteArraySet
与CopyOnWriteArrayList类似,但是是以Set的形式提供。 - EnumSet
高性能的Set实现,底层是位向量(bit vector)。EnumSet的元素均为枚举类型。 - EnumMap
高性能的Map实现,底层是数组。EnumMap的所有key君威枚举类型。
同步实现
JCF的同步实现保证了在多线程编程时的一致性。同步接口包括:
BlockingQueueTransferQueueBlockingDequeConcurrentMapConcurrentNavigableMap
同步实现类保证了集合的线程安全,是java.util.concurrent的一部分。
- ConcurrentLinkedQueue
非阻塞的FIFO并发队列,采用了CAS(Compare and Set)操作保证同步。CAS操作是指在set前compare该值有没有变化,只有没有变化时才对其赋值。底层由链表实现。 - LinkedBlockingQueue
阻塞的FIFO队列,采用了锁来保持同步,底层由链表实现。 - ArrayBlockingQueue
与LinkedBlockingQueu类似,但底层由数组实现。 - PriorityBlockingQueue
与ArrayBlockingQueue类似,但底层由堆(priority heap)实现。 - DelayQueue
基于时间调度的队列,底层由堆(priority heap)实现。 - SynchronousQueue
简单实现了阻塞机制的并发队列。 - LinkedBlockingDeque
与LinkedBlockingQueue类似,但是是双向队列。 - LinkedTransferQueue
由链表实现的TransferQueue, TransferQueue继承自BlockingQuque,并扩展了一些新方法。 - ConcurrentHashMap
基于Hashtable及ConcurrentMap的高性能同步实现,意味着其不仅实现了ConcurrentMap的所有方法,还支持Hashtable的所有旧方法。 - ConcurrentSkipListSet
线程安全的有序集合,可以视为TreeSet的同步实现,实现了NavigableSet接口。 - ConcurrentSkipListMap
线程安全的有序Map,可以视为TreeMap的同步实现,实现了ConcurrentNavigableMap接口,而ConcurrentNavigableMap接口继承自ConcurrentMap和NavigableMap。
算法
JCF的Collections类提供了一些有用的静态方法。
- sort(List)
利用归并排序算法将List排序。 - binarySearch(List, Object)
利用二分查找定位List中指定的元素。 - reverse(List)
将一个List反序。 - shuffle(List)
将List“洗牌”,打乱一个List的排序。 - fill(List, Object)
将List中的每个元素用指定对象覆盖。 - copy(List dest, List src)
将源List复制到目标List。 - min(Collection)
返回一个集合的最小值。 - max(Collection)
返回一个集合的最大值。 - rotate(List list, int distance)
整体移动一个List的元素,距离为正数时后移,负数时前移,e.g. 某个list的元素为[l, i, s, t], Collections.rotate(list, 1);之后list的元素为[t, l, i, s]。 - replaceAll(List list, Object oldVal, Object newVal)
将List中的所有某个值的元素替换为另外一个。 - indexOfSubList(List source, List target)
在List中返回子List第一次出现的索引值。 - lastIndexOfSubList(List source, List target)
在List中返回子List最后一次出现的索引值。 - swap(List, int, int)
交换List中两个指定索引的元素。 - frequency(Collection, Object)
统计集合中某个元素出现的次数。 - disjoint(Collection, Collection)
判断两个集合是否不含任何相同的元素。 - addAll(Collection<? super T>, T…)
将数组中的所有元素添加到集合中。
Infrastructure
基础支持提供了集合的一些基础功能。
Iterators
迭代器与Enumeration接口类似,但更加强大。
- Iterator
除了实现Enumeration接口的方法外,还能删除元素。 - ListIterator
针对List的迭代器,除了支持Iterator的功能外,还支持双向迭代,元素替换,元素插入以及索引获取。
Ordering
- Comparable
此接口的实现类要求各个元素可以自然排序,从而可以对整个集合排序,通常元素之间的顺序由equals方法的返回值得出。 - Comparator
当类本身不支持排序,即没有实现Comparable接口时,我们手动创建一个该类的比较器,同时重写排序方法,这个比较器只需要实现Comparator接口。
当然,如果类已经实现了Comparable接口,我们仍然可以利用比较器重新定义其排序方法。
Runtime exceptions
- UnsupportedOperationException
当集合进行不支持的操作时抛出。 - ConcurrentModificationException
当迭代正在进行,而集合被意外地修改了,由迭代器抛出该异常。
当List的sublist正在进行,而List被意外地修改了,同样抛出该异常。
Performance
- RandomAccess
实现了此接口的类需要支持快速的随机访问(random access),如随意访问List中的任意索引的元素。
Array Utilities
数组的工具主要指Arrays类提供的方法。
- Arrays
Arrays类包含一系列的静态方法,包括排序,查找,比较,哈希,复制,改变大小,转换成String以及使用对象或基本类型填充数组等功能。
类库结构
下面这张图详细描述了集合框架的类结构,注意并不是完整的,比如缺失了Deque部分。
也可以参考下面这张图。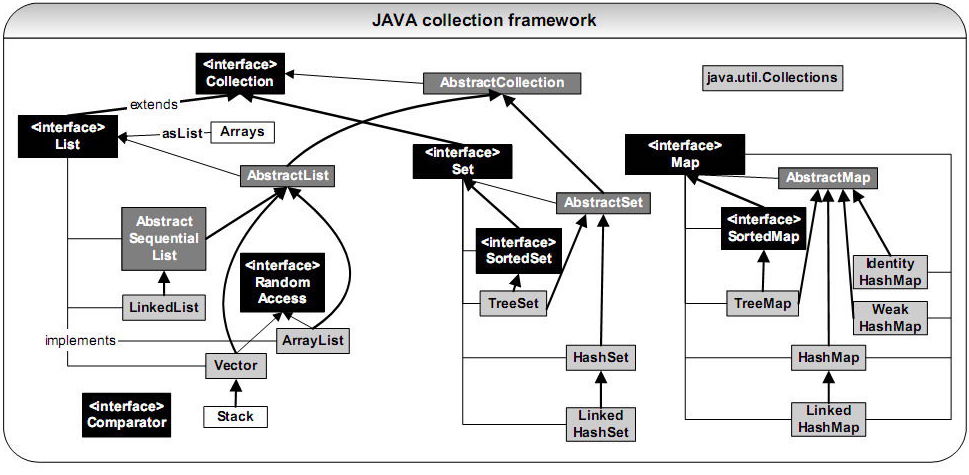
Iterable
上面的体系图中没有画出的接口Iterable是Collection接口的父接口。
Iterable接口声明了iterator方法,用于生成一个Iterator迭代器。
在Java 1.8中,还声明了新的forEach方法,同时提供了默认实现,用于使用lambda表达式进行遍历,下面的例子中展示了这种用法,由于List实现了Collection接口,也继承了Iterable的forEach方法。1
2
3
4
5List<String> list = Arrays.asList(new String[]{"Hello", " ", "World!"});
//lambda表达式遍历
list.forEach(s -> System.out.println(s));
//lambda表达式遍历简化版
list.forEach(System.out::println);
Java 1.8也声明了spliterator方法并提供了默认实现,spliterator是一种用于并行迭代数据源中元素的迭代器。
Collection
Collection接口是集合框架的“根接口”之一,其声明了许多集合实现类共有的方法。
基本操作
集合的一些基本操作包括如下方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//获取集合元素的个数
int size();
//判断集合是否为空
boolean isEmpty();
//判断集合是否包含某元素
boolean contains(Object o);
//获取迭代器,继承自Iterable接口
Iterator<E> iterator();
//将集合转换成Object数组
Object[] toArray();
//与toArray类似,如果参数a数组的长度小于集合的大小, 则不填充, 等同于toArray(),否则填充a数组,此时返回的数组与a相同
<T> T[] toArray(T[] a);
//添加元素
boolean add(E e);
//删除元素
boolean remove(Object o);
//判断集合是否是指定集合的超集
boolean containsAll(Collection<?> c);
//将指定集合添加进本集合
boolean addAll(Collection<? extends E> c);
//将指定集合从本集合中移除
boolean removeAll(Collection<?> c);
//保留指定集合的所有元素, 移除本集合中的其他所有元素
boolean retainAll(Collection<?> c);
//清空集合
void clear();
比对
用于判断集合对象的相等的方法声明,需要子类实现。1
2boolean equals(Object o);
int hashCode();
Java 1.8
Java 1.8中的新方法均提供了默认实现。1
2
3
4
5
6
7
8//since 1.8
default boolean removeIf(Predicate<? super E> filter){...}
//since 1.8
default Spliterator<E> spliterator() {...}
//since 1.8
default Stream<E> stream() {...}
//since 1.8
default Stream<E> parallelStream() {...}
其中Stream和parallelStream返回的是Stream,区别在于是否并行计算。Stream的作用类似于一个一次性的迭代器,只能单向地遍历数据源一次,有点filter-map-reduce的意思,最终产生一个结果。例如有以下类Transcation。1
2
3
4
5
6
7
8
9public Class Transaction {
public static final String GROCERY = "grocery";
public static final String DRINK = "drink";
public static final String COMMODITY = "commodity";
private int id;
private int value;
private String type;
//...getters + setters
}
要获取顺序排列的类型为grocery的Transaction id List,在Java 1.7会经过筛选、排序、遍历获取id三个过程,需要一个额外的中间List。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16List<Transaction> groceryTransactions = new Arraylist<>();
//transactions为源Transaction List
for(Transaction t: transactions){
if(t.getType() == Transaction.GROCERY){
groceryTransactions.add(t);
}
}
Collections.sort(groceryTransactions, new Comparator(){
public int compare(Transaction t1, Transaction t2){
return t2.getValue().compareTo(t1.getValue());
}
});
List<Integer> transactionIds = new ArrayList<>();
for(Transaction t: groceryTransactions){
transactionsIds.add(t.getId());
}
而在Java 1.8,借助于Stream和lambda表达式,大部分工作被简化了,Developer可以更专注于业务了。1
2
3
4
5List<Integer> transactionsIds = transactions.parallelStream().
filter(t -> t.getType() == Transaction.GROCERY).
sorted(comparing(Transaction::getValue).reversed()).
map(Transaction::getId).
collect(toList());
AbstractCollection
AbstractCollection抽象类提供了Collection接口的部分骨干实现,为其子类减少了实现Collection接口所需的工作。在JCF中,AbstractCollection的直接子类包括AbstractList, AbstractQueue以及AbstractSet。
不可修改集合
继承自AbstractCollection的类要实现一个不可修改的集合,需要实现iterator及size方法,且iterator方法返回的迭代器:Iterator接口的实现类,还必须重写其remove方法,因为AbstractCollection只是声明了iterator方法,1
public abstract Iterator<E> iterator();
且iterator方法被其他方法调用(e.g. contains方法),而Iterator类的默认remove方法如下(Java 1.7中没有默认实现,仍为抽象方法):1
2
3default void remove() {
throw new UnsupportedOperationException("remove");
}
可见,若不重写则不然抛出UnsupportedOperationException异常。
可修改集合
要实现一个可修改的集合,在不可修改集合的基础上,除了实现iterator及size方法,还需要重写其add方法,因为AbstractCollection定义的add方法是:1
2
3public boolean add(E e) {
throw new UnsupportedOperationException();
}
可见,若不重写则必然抛出UnsupportedOperationException异常。
List
List继承自Collection接口,有序且允许元素重复,三个直接实现包括ArrayList,LinkedList及Vector,以及继承自Vector的间接继承类Stack。
List以线性方式存储元素,具有索引的概念,因此允许根据索引来随机访问元素。默认构造时产生10个元素大小的空List。
由于其继承自Collection接口,因此其继承了Collection所有不含默认实现的方法。常用的方法包括但不限于:添加及访问元素、删除元素、清空List、获取List大小、遍历List。
ArrayList
List最常用的通用实现是ArrayList。ArrayList底层由一个Object数组维护,构造时会设置一个初始的容量,当元素增加时,ArrayList会去自动扩容;必要时,如元素是大对象时,也可以手动给其缩容。
构造
三个构造函数分别是:public ArrayList(Collection<? extends E> c);public ArrayList();public ArrayList(int initialCapacity);
对于第一个构造方法,核心是调用Arrays.copyOf()方法来进行复制,而对于空的源集合,则创建一个空的ArrayList。
在Java 1.7-,ArrayList()直接调用ArrayList(10),而ArrayList(int initialCapacity)直接通过参数的正负抛出异常或创建指定大小的数组。
而在Java 1.8+,ArrayList()会直接将一个DEFAULTCAPACITY_EMPTY_ELEMENTDATA赋给数组,其实际上是一个空的Object数组;ArrayList(int initialCapacity)会区分得更细,根据参数的为正、为零、或为负分别创建指定大小的数组、将一个EMPTY_ELEMENTDATA空数组赋值给数组、抛出异常。
动态扩容
ArrayList在添加元素前,会确保容量够大,如果不足将进行扩容。
添加前,会调用ensureCapacityInternal(size + 1),size为当前的元素个数。抛开对于溢出情况的限制逻辑,扩容的关键语句(Java 1.7+)是:1
2int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
而在Java 1.6-,是这样做的:1
int newCapacity = (oldCapacity * 3)/2 + 1;
在Java 1.6-,新容量为原容量的1.5倍加1,而在Java 1.7+,新容量为原容量的1.5倍。显然,位运算的容量计算效率更高一些。
确定了newCapacity后,会新申请一个长度为newCapacity的Object数组,接着调用Arrays.copyOf方法,将原数组拷贝过去。因为扩容是通过将整个数组拷贝的方式来完成的,对于大对象的数组时,性能问题需要仔细考虑,因此最好提前规划好容量,降低扩容频率。
Vector
Vector与ArrayList的区别在于ArrayList不是线程安全的,而Vector通过加同步锁的方式保证了线程安全,而且读和写都是简单地加上synchronized修饰符(e.g. size方法, get方法),导致其性能比较差。
扩容时,如果调用了指定容量初值及容量增量的构造方法public Vector(int intialCapacity, int capacityIncrement);,且增量为正整数,则按照指定的增量来扩容;如果调用的是指定了容量初值的构造方法public Vector(int initialCapacity);,则每次扩容将容量扩大一倍。如果调用了空参数的构造方法public Vector();则等同于public Vector(10);。
LinkedList
LinkedList同时实现了List接口与Deque接口,它是一个双向链表。每次插入时可以选择在链表头或者链表尾插入,读取时需要从链式结构逐个遍历,而删除时则是我们熟悉的断链-重链过程。
与ArrayList的区别即链表与线性表的区别:不需要预估容量及动态扩容,每次新增时只需要新增一个链上的节点,代价是遍历时需要从链上逐个遍历,不支持随机访问。
Set
Set继承自Collection接口,因为访问其中的元素时为直接访问其对象的引用,故不能有重复元素,且最多有一个为null值的元素。值的注意的是Set接口并没有声明get方法,因此具体如何访问Set中的元素需要实现类来定义。
Set接口有一个子接口SortedSet,一个抽象实现类AbstractSet,两个通用实现类HashSet,TreeSet。
AbstractSet
AbstractSet抽象类实现了Set接口,且是AbstractCollection的子类,其添加了hashCode和equals方法的实现,用于对比两个集合的相等性。
hashCode方法遍历集合中的所有元素,返回它们的hashCode之和,因此两个包含相同元素集的集合hashCode值应该相等。equals方法则先比对两个集合的size,再调用AbstractCollection的containsAll方法,比对每个元素的相等性。
SortedSet
SortedSet接口继承自Set接口,它要求实现类必须保证元素有序,顺序为自然顺序或comparator方法定义的顺序。
SortedSet声明的元素访问方法包括E first(),E last(),SortedSet<E> tailSet(E fromElement);,SortedSet<E> headSet(E toElement);以及SortedSet<E> subSet(E fromElement, E toElement);。可见SortedSet只为单个元素提供了头部或尾部的访问。
NavigableSet
NavigableSet接口是SortedSet的子接口,顾名思义就是可以导航的Set,其提供的lower, floor, ceiling, higher四个方法,允许其根据定位小于、小于等于、大于等于、大于指定元素的一个元素。
针对排序,NavigableSet接口声明了NavigableSet<E> descendingSet();及Iterator<E> descendingIterator();方法,后者相当于前者的返回结果再调用iterator方法。这两个方法提供了一个由原NavigableSet反序排列的NavigableSet,或其迭代器。
NavigableSet中的pollFirst及pollLast方法将移除并返回集合第一个或最后一个元素。
Map
Map是一个独立的接口,元素为一个个的Entry,每个Entry为Key-Value对,Key与Value可以是任意Object,但由于要根据Key来区分不同的Entry,因此Key不能重复,但Value可以重复(包括null)。
基本操作
Map接口定义了一些与Collection相似的常用方法,以及一些Map独有的方法。此外,Map接口还分别为Key和Value规定了两个范型<K, V>。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//获取集合元素的个数
int size();
//判断集合是否为空
boolean isEmpty();
//检查是否包含指定的Key
boolean containsKey(Object key);
//检查是否包含指定的Value
boolean containsValue(Object value);
//根据Key获取Value
V get(Object key);
//添加Entry
V put(K key, V value);
//根据Key删除Entry
V remove(Object key);
//与Collection接口的addAll类似,将指定的Map对象添加进此Map
void putAll(Map<? extends K, ? extends V> m);
//清空Map中的所有元素
void clear();
//将所有的Key作为一个Set读取
Set<K> keySet();
//将所有的Value作为一个集合读取
Collection<V> values();
//将所有的Entry作为一个Set读取
Set<Map.Entry<K, V>> entrySet();
比对
用于判断两个Map对象的相等的方法声明,需要子类实现。1
2int hashCode();
boolean equals(Object o);
Java 1.8
Map在Java 1.8的新方法均有默认实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//与get方法类似, 但当获取不到对应的Value时, 返回指定的默认Value
default V getOrDefault(Object key, V defaultValue){...}
//与put方法类似, 当不存在对应的Entry时put并返回null, 若存在则返回Value
default V putIfAbsent(K key, V value){...}
//只有当Map中存在Entry包含指定的Key-Value时, 才删除该Entry
default boolean remove(Object key, Object value){...}
//只有当Map中存在Entry包含指定的Key以及Value时, 才用新的Value替换旧Value
default boolean replace(K key, V oldValue, V newValue){...}
//只有当Map中存在Entry包含指定的Key以及任意Value时, 才用新的Value替换旧Value, 返回旧Value或null(如果没替换或原Key映射的Value为null)
default V replace(K key, V value){...}
//用于构建本地缓存
default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction){...}
default V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction){...}
default V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction){...}
//用于Map的合并
default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction);
//遍历
default void forEach(BiConsumer<? super K, ? super V> action);
//全部替换
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function);
Map.Entry
之前提到keySet, values以及entrySet方法,与Map中的Entry息息相关,Entry是Map接口中重要的内部接口。
Entry沿用了Map接口的范型<K, V>,代表的是Map中每一个单独的元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19interface Entry<K,V> {
//获取此Entry的Key
K getKey();
//获取此Entry的Value
V getValue();
//设置此Entry的Value
V setValue(V value);
//equals及hashCode用于判断两个Entry对象的相等
boolean equals(Object o);
int hashCode();
//since 1.8, 返回一个根据Key来比对的比较器, 可用于排序
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {...}
//since 1.8, 返回一个根据Value来比对的比较器, 可用于排序
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {...}
//since 1.8, 返回一个根据Key来比对的比较器, 但比对方式来源于入参比较器
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {...}
//since 1.8, 返回一个根据Value来比对的比较器, 但比对方式来源于入参比较器
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {...}
}
Map接口主要有HashMap, Hashtable, EnumMap, IdentityHashMap, LinkedHashMap,Properties, TreeMap, WeakHashMap这几个直接或间接实现。
AbstractMap
作为Map的抽象实现类,AbstractMap为Map的实现类预先实现了许多Map接口声明的方法,包括size, isEmpty, containsValue, containsKey, get, put, remove, putAll, clear, keySet, values, hashCode, equals等等,但这些方法大都依赖于entrySet方法,而AbstractMap并未实现entrySet方法,而是留待其子类来实现,从而产生不同变种的Map。
此外,AbstractMap还提供了两个实现了Map.Entry1
2
3
4
5
6public static class SimpleEntry<K,V> implements Entry<K,V>, java.io.Serializable {
//声明key为final确保了Entry对象内key一旦被设置后就不可再修改
private final K key;
private V value;
...//方法实现
}
1 | public static class SimpleImmutableEntry<K,V> implements Entry<K,V>, java.io.Serializable { |
HashMap
HashMap是Map接口最常见的实现类,继承自AbstractMap,不保证迭代时元素的顺序。
桶
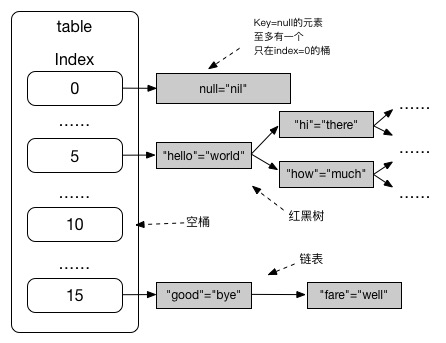
HashMap的数据结构是一个数组,数组的每个索引下存放一组元素,这组元素称为桶(bucket)。在Java 1.7-,桶中的元素以链表的形式组织起来,而在Java 1.8+,桶中元素首先会以链表形式组织,当桶中元素数量超过阈值时,将其变为红黑树的形式组织。
散列
HashMap的设计使得元素新增时,能均匀地分布在各个桶里。那么每当有元素加入时,如何判断该元素应该存放到哪个桶中呢?答案是散列,就是按一定的算法(hash方法)根据元素的hashCode计算出其所属的桶在数组中的索引。当该索引没有任何元素时,将该元素作为头元素存放在桶中;当该索引有元素时,此时称为冲突或碰撞,需要遍历到该桶的元素,如果有相同Key的元素,则将其Value更新,否则将该元素作为新的头元素加入桶中(头插法)。
当冲突过于频繁时,即大部分新增元素都落到一个桶中时,HashMap退化为链表,或红黑树(Java 1.8)。
由于HashMap在Java 1.7-与Java 1.8+中的实现差别较大,因此需要分开研究。
下面两张图分别是Java 1.7和Java 1.8的HashMap实现示意图。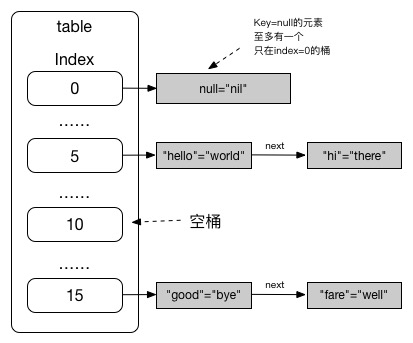
HashMap.Entry
Java 1.7的HashMap内部有一个静态类Entry1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
...//其它方法
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
}
从HashMap.Entry
- Entry直接实现了Map接口的Entry内部接口,没有使用AbstractMap提供的对Entry的内部实现类。
- 一个Entry的key值是设置后不可变的。
- Entry与Entry之间以单向链表的形式组织起来,前一个Entry持有下一个Entry的引用。
- hashCode方法先用工具类Objects分别对Key和Value进行hashCode计算,再将两个结果按位异或。而工具类Objects的hashCode方法中,如果对象是null返回0,否则调用native的hashCode方法求值。
- Entry的equals方法中分别比对当前对象和目标对象的Key和Value。
存放(Java 1.7)
常量及变量
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 |
以上变量及常量与HashMap的元素存放有关。
- DEFAULT_INITIAL_CAPACITY
代表默认的初始容量,为16。 - MAXIMUM_CAPACITY
代表默认的最大容量,为1左移30位。 - DEFAULT_LOAD_FACTOR
代表默认的负载因子,为0.75,即四分之三。 - table
用于存放元素,每一个索引存放一个桶(链表)的头元素,根据需要可以扩容,其长度只能为0或2的n次方。 - entrySet
以Set的方式对Entry进行缓存。 - size
指示HashMap中有实际有多少个Key-Value对的元素。 - threshold
指示下次变容后的size大小,即实际容量*loadFactory,初始的threshold可以在构造方法内指定(initialCapacity),若没有指定则为DEFAULT_INITIAL_CAPACITY。 - loadFactory
指的是负载因子,可以在构造方法中指定,若没有指定则为DEFAULT_LOAD_FACTOR。
hash
1 | final int hash(Object k) { |
这是Java 1.7的hash方法,我们不需要纠结于具体如何hash,只需要知道根据不同的Key会分配到或许相同或许不同的数组索引下,且分配是较为均匀的。
计算完hash后,还需要调用indexFor方法来计算数组索引,从而确定存放在哪个桶。
indexFor
1 | static int indexFor(int h, int length) { |
indexFor相当于根据Key的hash值对数组的长度取模,用于确定Entry分配到哪个索引下的桶。
resize
1 | void resize(int newCapacity) { |
resize的关键在于,当新容量与负载因子的乘积(newCapacity * loadFactor)小于默认的最大容量时,threshold变为这个乘积,否则变为默认的最大容量,同时不再扩容。
addEntry
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
可见,每当调用addEntry时,若当前容量达到了threshold,且欲将元素添加进的桶不为空时,将容量扩为原来的两倍。
而createEntry则是根据索引定位桶,再将新的Key-Value对作为Entry放在该索引下的桶(链表)的头元素上,同时将原来的头元素引用为其next变量。
put
1 | public V put(K key, V value) { |
当Key为null时,调用putForNullKey方法,其实就是把Key-Value放在索引为0的桶内。
当Key为非null时:根据Key求hash值->根据hash值计算索引,定位要存放的桶->遍历该桶内的元素,如果找到相同Key的元素,则更新该Entry,返回旧的Value;如果找不到,则调用addEntry方法,将该Key-Value插在桶(链表)头部,返回null。
HashMap.Node
Java 1.7的HashMap结构非常简单,
在Java 1.8中,HashMap的静态内部类Entry被改为Node1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
从HashMap.Node
- Node直接实现了Map接口的Entry内部接口,没有使用AbstractMap提供的对Entry的内部实现类。
- 一个Node的key值是设置后不可变的。
- Node与Node之间以单向链表的形式组织起来,前一个Node持有下一个Node的引用。
- Node的hashCode方法中与Java 1.7中HashMap.Entry
- Node的equals方法中调用了Objects类的equals方法,分别比对当前对象和目标对象的Key和Value。而Objects类的equals方法中,只有当两个对象均为null或者”==”成立时才返回true。
存放(Java 1.8)
与Java 1.7相比,在Java 1.8中,HashMap的存放方式发生了很大的变化。Java 1.7中,HashMap的元素存放在桶数组中,每个桶是一个链表;而在1.8中,元素也是存放在桶数组中,一开始每个桶也是一个链表,但当桶内元素数达到一定的值时,桶中元素的数据结构由链表变为了红黑树。
关于红黑树的结构,不做具体展开。
常量与变量
1 | transient Node<K,V>[] table; |
以上变量及常量与HashMap的元素存放有关,其它常量及变量与Java 1.7相同。
- TREEIFY_THRESHOLD
代表当一个桶中的元素数达到该值时,就将该桶从链表(若仍是链表)转化为红黑树。 - UNTREEIFY_THRESHOLD
代表的当一个桶中的元素被移除时,若其中的元素达到该值时,就将该桶从红黑树(若已经是红黑树)转化为链表。 - MIN_TREEIFY_CAPACITY
代表只有当数组的长度达到该值时,链表转化为红黑树的情况才会发生,至少为TREEIFY_THRESHOLD的四倍。 - table
在Java 1.8中以Node数组存放桶及元素,根据需要可以扩容,其长度只能为0或2的n次方。
hash
这是Java 1.8的hash方法。1
2
3
4static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
当Key为null时返回0,否则将Key的hashCode与其hashCode无符号右移16位的结果(忽略符号位,空位以0补齐)进行按位异或运算。
putVal
其实际对Key进行了hash运算,同时带着Value和一些flag调用了putVal方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果是空的HashMap,则先resize为默认初始容量,并得到扩容后的数组长度。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//Key的hash值同数组最大索引按位与运算,得到存放元素的索引,如果该索引没有元素,则在该索引处新建元素
//此处与Java 1.7的indexFor方法基本一样
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果该索引已经存在元素
else {
Node<K,V> e; K k;
//入参Key与该索引的第一个元素相等,即该元素为头元素,将更新该元素的Value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果该索引的元素已经是红黑树结构,则调用红黑树的putTreeVal方法,获取元素(遍历找不到入参Key对应的元素时,用于更新)或直接新建元素返回null(遍历找不到入参Key对应的元素时)
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果该索引的元素是链表结构
else {
//从该索引的头元素开始,遍历链表
for (int binCount = 0; ; ++binCount) {
//发现当前元素的下一个元素为null,即当前元素为该索引下链表的尾元素
if ((e = p.next) == null) {
//则新建入参Key和Value的元素,同时处理好链条关系
p.next = newNode(hash, key, value, null);
//如果当前链表的节点数不小于阈值,则将该链表转为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//成功新建或获取到了需要更新的元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//找到了入参Key对应的元素,更新其Value
if (e != null) { // existing mapping for key
...
e.value = value;
return oldValue;
}
}
...//其他代码
//如果put后的容量大于threshold,则进行扩容
if (++size > threshold)
resize();
...//其他代码
//如果是新建元素,返回null
return null;
}
put
以下是我们熟悉的put方法。1
2
3public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
获取
由于Java 1.7的HashMap结构较为简单,因此其get方法也是简单明了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//获取Key的hash值
int hash = (key == null) ? 0 : hash(key);
//调用indexFor方法确定Key对应的元素所在的桶,如果桶不为空则遍历桶上的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//找到了对应的元素,返回Entry
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
//根据Key的hash值获取不到桶,不存在该Key对应的Entry
return null;
}
1 | public V get(Object key) { |
而在Java 1.8,情况变得稍微复杂了一些。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25final Node<K,V> getNode(int hash, Object key) {
//合并了indexFor方法,直接传入Key的hash值
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//如果数组不为空,且根据Key的hash值获取的桶不为空(头元素非null)
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//如果Key对应的元素是该桶的头元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果不是头元素
if ((e = first.next) != null) {
//如果该桶已经是红黑树结构,调用获取红黑树节点的方法getTreeNode
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//如果该桶仍是链表结构,遍历该链表,如果找到则返回该Node
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
1 | public V get(Object key) { |
HashMap vs Hashtable
Hashtable属于旧的集合实现(legacy),对大部分方法通过synchronized关键字加了同步锁,虽然保证了线程同步,但效率不高。HashMap没有加锁,性能更佳,但并不适用于多线程环境,多线程环境下应使用ConcurrentHashMap。
SortedMap
SortedMap是继承自Map的接口,其定义了一种遍历顺序一定的Map。
SortedMap要求其实现类必须保证内部元素可以按自然或Comparator的顺序排列。
此接口很抽象,也允许很大的实现空间。
NavigableMap
NavigableMap继承自SortedMap接口,顾名思义,就是可以导航的Map。
descendingKeySet及descendingMap
返回一个当前的Key Set反序的Key Set或当前Map反序的Map。
headMap, tailMap及subMap
返回一个“小于”、大于、或在某两个元素区间内(不含)的子Map。
ceilingKey, floorKey, higherKey及lowerKey
返回一个“不小于”、“不大于”、“大于”、“小于”某个指定Key的Key。
celingEntry, floorEntry, higherEntry, lowerEntry
返回一个“不小于”、“不大于”、“大于”、“小于”某个指定Entry的Entry。
pollFirstEntry() and pollLastEntry()
删除并返回第一个或最后一个Entry。
TreeMap
TreeMap是NavigableMap接口的实现。
TreeMap包含一个静态内部类TreeMap.Entry,作为TreeMap的元素,其数据结构为红黑树,能保证元素的有序遍历。
HashSet
HashSet继承自AbstractSet,其内部有一个很奇妙的成员变量:1
private transient HashMap<E,Object> map;
其底层实现其实是由HashMap来实现的。
说白了,HashSet的核心其实就是一个只使用HashMap的Key及KeySet的子类。1
2
3
4private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
可见,每次往HashSet添加元素时,都会把元素作为Key添加进来,同时新建一个Object对象,用于填充其内部HashMap的Value。
LinkedHashSet
HashSet的子类,虽然添加元素时与HashSet相同,即根据元素的hashCode来将其散列存储到某个桶中,但是使用了一个双向链表记录插入顺序,遍历时依照的就是这个插入顺序。
对于同一个元素,其插入顺序不会因为多次插入而变化。只有当其被移除后再次插入时,其顺序才会改变。
TreeSet
AbstractSet的子类,同时实现了NavigableSet接口。
TreeSet与TreeMap的关系,如同HashSet与HashMap的关系。1
2
3
4
5
6
7
8private transient NavigableMap<E,Object> m;
public TreeSet() {
this(new TreeMap<E,Object>());
}
private static final Object PRESENT = new Object();
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
TreeSet的元素保证有序,按照自然顺序或指定的Comparator的排序规则排序。
TreeSet中的descendingSet, headSet, tailSet, subSet, ceiling, floor, higher, lower, pollFirst, pollLast等方法与TreeMap(NavigableMap)中类似名称的方法起着类似作用。
Queue
Queue接口继承自Collection接口,其声明了如下方法。1
2
3
4
5
6
7
8
9
10
11
12//往队列尾添加元素, 成功返回true,否则抛出异常
boolean add(E e);
//往队列尾添加元素,成功返回true,否则返回false或抛出异常
boolean offer(E e);
//移除队列头元素,并返回该元素,如果为空则抛出异常
E remove();
//移除队列头元素,并返回该元素,如果为空则返回null
E poll();
//返回队列头元素,如果为空则抛出异常
E element();
//返回队列头元素,如果为空则返回null
E peek();
Deque
Deque接口继承自Queue接口,全称是Double ended queue,即双端队列,允许在队列两端入队(offer)及出队(poll),这使得Deque的实现类既可以是栈,也可以是队列。
当Deque的实现类是FIFO的队列时,元素被插入在Deque的尾部,而Deque头部的元素先被删除。以下是Queue接口中声明的方法在Deque作为队列时对应的方法。
| Queue | Deque |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
Deque的实现类也可以作为LIFO的栈使用,作为旧集合类Stack的替代,此时元素被插入在Deque头部,而Deque头部的元素也最先被删除。以下是Stack类中定义的方法在Deque作为栈时对应的方法。
| Stack | Deque |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
无论Deque作为队列或栈使用时,peek方法都返回头部元素。
与List接口不同,Deque不提供对元素的索引访问。
虽然Deque允许插入null元素,但其实现类不应允许,因为有时null是某些方法的特殊返回值。
Deque有两个通用实现类LinkedList及ArrayDeque。
LinkedList & ArrayDeque
LinkedList类实现了List接口及Deque接口,其内部实现是一个双向链表。
ArrayDeque类继承自AbstractCollection类并实现了Deque接口,其内部实现是一个数组。
这两个Deque实现类的使用方法类似,但由于同时暴露了Deque的FIFO方法及LIFO方法,因此如果我们想要实现一个“纯粹”的队列或栈,还需要亲自动手封装。
Deque队列 & Deque栈
以下是一个手动封装Deque的简单示例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class MyQueue <T>{
private Deque<T> elements;
public MyQueue(){
elements = new ArrayDeque<>();
}
/**
* 添加至队尾
* @param e
*/
public void enqueue(T e) {
elements.addLast(e);;
}
/**
* 队头元素先出队列
* @return
*/
public T dequeue() {
try {
return elements.removeFirst();
} catch (NoSuchElementException e) {
return null;
}
}
public T peek() {
return elements.peekFirst();
}
}
1 | public class MyStack <T>{ |
1 | public class Test { |
Arrays
Arrays工具类提供的asList静态方法能将数组转化为List。1
2
3
4Integer[] arr = new Integer[]{1,2,3};
List<Integer> list = Arrays.asList(arr);
int[] arr2 = new int[]{1,2,3};
List<?> list2 = Arrays.asList(arr);
Iterator
Iterator是迭代器,可用于遍历集合对象,以下以Map为例,Set的Iterator同理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public static void main(String[] args) {
Map<Integer, Object> map = new HashMap<>();
map.put(1, "a");map.put(2, "b");map.put(3, "c");
Iterator<Integer> iterator = map.keySet().iterator();
//差劲的遍历方法,迭代key,每次根据key再get
while(iterator.hasNext()) {
Integer key = iterator.next();
System.out.println(key + "=" + map.get(key));
}
//一般遍历方法,entrySet是一个Set实现类,返回一个Iterator对象
Iterator<?> iterator2 = map.entrySet().iterator();
while(iterator2.hasNext()) {
System.out.println(iterator2.next());
}
//一般遍历方法,在Java 1.7-最常见
for(Map.Entry<Integer, Object> entry: map.entrySet()) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
//Java 1.8中的遍历方法,利用lambda表达式简化了语句,forEach内部实现其实仍是一般方法
map.forEach((k, v)->{
System.out.println(k + "=" + v);
});
//进一步简化
map.forEach((k, v)->System.out.println(k + "=" + v));
}
Collections
提供大量处理集合类的静态方法。1
2
3
4
5
6
7
8
9public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(3);list.add(2);list.add(1);
System.out.println(Collections.binarySearch(list, 2)); //index of '2' = 1
System.out.println(Collections.max(list)); //max = 3
System.out.println(Collections.min(list)); //min = 1
Collections.sort(list); //list=[1, 2, 3]
Collections.reverse(list); //list[3, 2, 1]
}
参考资料
The Collections Framework - Oracle Java Documentation
Javadoc 8 - Oracle Java Documentation